In jedem Programm werden Informationen verarbeitet. Diese Informationen liegen im Speicher. Höhere Programmiersprachen greifen nicht direkt auf den Speicher zu, sondern verwenden Variablen. Variablen sind also die Behälter, in denen das Programm Zahlen und Texte ablegt. Eine Variable hat drei wichtige Eigenschaften:
- Speicher: Die Variable benötigt zum Ablegen ihrer Informationen immer
Speicher. Der Speicher wird der Variablen vom Compiler zur Verfügung gestellt.
Über Lage und Größe des Speichers braucht sich der Programmierer normalerweise
nicht zu kümmern. Der Compiler ermittelt die Größe aus dem Typ der Variablen
und sorgt dafür, dass der verwendete Speicher nicht anderweitig belegt wird.
- Name: Die Variable wird im Programm über einen weit gehend frei wählbaren
Namen angesprochen. Dieser Name identifiziert die Variable eindeutig.
Verschiedene Namen bezeichnen verschiedene Variablen. C++ unterscheidet
zwischen Groß- und Kleinschreibung. Der Name »Var« ist ein anderer als
der Name »var«. Die Namensregeln gelten
f³r alle Namen in C++.
- Typ: Der Typ einer Variablen bestimmt, welche Informationen abgelegt werden können. So kann eine Variable je nach ihrem Typ beispielsweise einen Buchstaben oder eine Zahl speichern. Der Typ bestimmt natürlich auch die Speichergröße, die benötigt wird. Der Typ bestimmt aber auch, welche Operationen auf die Variable angewendet werden können. So können Sie beispielsweise Zahlen durch einander dividieren. Mit Texten geht das nicht.
Variablendefinition
Das folgende Beispiel zeigt eine Variablendefinition innerhalb der Hauptfunktion main():
[Variablendefinition]
main()
{
int Einkommen;
}
Typ
Eine Variablendefinition beginnt immer mit dem Typ der Variablen. Hier heißt der Typ int. Dieser Typ steht für eine ganze Zahl mit Vorzeichen, aber ohne Nachkommastellen (Integer).
Variablennamen
Durch ein Leerzeichen abgesetzt, beginnt der Name der Variablen. Den Namen sollten Sie immer so wählen, dass Sie auf den Inhalt schließen können. Hier lässt der Name Einkommen bereits auf die Verwendung der Variablen im Programm schließen. Verwenden Sie ruhig lange Namen. Abkürzungen ersparen zwar Tipparbeit, Sie werden aber auf lange Sicht mehr Zeit verschwenden, wenn Sie darüber nachdenken müssen, was in welcher Variable abgelegt ist. Das gilt auch dann, wenn Sie extrem langsam tippen. Noch mehr Zeit werden Sie brauchen, wenn Sie einen Fehler suchen müssen, der entstand, weil Sie zwei Variablen verwechselt haben, nur weil der Name unklar war.
Semikolon
Zu guter Letzt folgt das Semikolon. Damit wird jede Anweisung abgeschlossen, auch eine Variablendefinition.
Initialisierung
Sie können Variablen gleich bei ihrer Definition mit einem Wert vorbelegen. Dazu setzen Sie hinter den Variablennamen ein Gleichheitszeichen. Das initialisiert die Variable mit dem nachfolgenden Wert.
int Einkommen=0;
Hier wird die Variable Einkommen gleich bei der Definition auf null gesetzt. (Ein Vorgang, der vielen Informatikern aus ihrer eigenen Erfahrungswelt sehr bekannt vorkommt.) Die Initialisierung von Variablen muss nicht zwingend durchgeführt werden. Allerdings ergeben sich viele Programmfehler daraus, dass Variablen nicht korrekt initialisiert waren. Es ist keineswegs gesichert, dass eine neu angelegte Variable den Wert 0 hat, solange Sie das nicht explizit festlegen.
Anstatt eine Initialisierung mit dem Gleichheitszeichen durchzuführen, kann in C++ auch eine Klammer verwendet werden. Das obige Beispiel sähe in dieser Syntax so aus:
int Einkommen(0);
Mehrfache Definition
Es können mehrere Variablen gleichen Typs direkt hintereinander definiert werden, indem sie durch Kommata getrennt werden.
int i, j=0, k;
Hier werden die Variablen i, j und k definiert. j wird mit 0 initialisiert. Diese Schreibweise ist mit der folgenden gleichwertig:
int i; int j=0; int k;
Weiter unten finden Sie einen Syntaxgraph zur Variablendefinition.
Geltungsbereich
Deklarationspflicht
Sie können in C++ eine Variable erst verwenden, nachdem Sie sie deklariert haben. Der Compiler prüft, ob die Variable ihrem Typ gemäß verwendet wird. Es gibt Programmiersprachen, die eine Variable automatisch anlegen, sobald sie das erste Mal verwandt wird. Dieser Komfort wird tückisch, wenn Sie eine Variable namens AbteilungsNr versehentlich an anderer Stelle ohne s, also als AbteilungNr bezeichnen. Sie werden vom Compiler nicht auf Ihren Tippfehler hingewiesen. Stattdessen arbeiten Sie mit zwei unterschiedlichen Variablen, ohne es zu ahnen. Das kann Ihnen in C++ nicht passieren. Der Compiler wird sofort nörgeln, dass er die Variable AbteilungNr überhaupt nicht kennt, und er wird sich weigern, mit einer solchen Variablen irgendetwas zu tun. Sie werden also sofort auf Ihren Fehler hingewiesen und können ihn korrigieren.
Blockgrenzen
Während in C Variablendefinitionen nur am Blockanfang vor der ersten Anweisung erlaubt sind, kann in C++ eine Variable überall definiert werden. Sie gilt dann für den gesamten restlichen Bereich des aktuellen Blocks und aller darin verschachtelten Blöcke.Es können sogar in verschachtelten Blöcken Variablen mit dem gleichen Namen verwendet werden. Dabei überdeckt die innen liegende Definition diejenige, die außerhalb des Blocks liegt. Folgendes Beispiel macht das deutlich:
[Zwei Variablen]
{
int a = 5;
{
// hier hat a den Inhalt 5
}
{
int a = 3;
// hier hat a den Inhalt 3
{
// a ist immer noch 3
}
}
// hier ist a wieder 5
}
Lokale Variable
Die innere Variable wird als lokale Variable bezeichnet. Für ihren Geltungsbereich überdeckt sie die außen liegende Variable a. Die außen liegende Variable existiert durchaus noch, aber aufgrund der Namensgleichheit mit der lokalen Variablen kann man bis zu deren Auflösung nicht auf sie zugreifen. Sobald das Programm den Block verlässt, in dem die lokale Variable definiert ist, wird die äußere Variable wieder sichtbar. Alle Operationen auf der lokalen Variablen berühren die äußere Variable nicht.
globale Variable
Variablen, die außerhalb jedes Blocks definiert werden, nennt man globale Variablen. Sie gelten für alle Blöcke, die nach der Definition im Quelltext auftreten, sofern darin nicht eine Variable gleichen Namens lokal definiert wird.
Initialisierung
Globale Variablen werden bei C++ grundsätzlich vom Compiler mit null initialisiert, sofern das Programm nicht eine eigene Initialisierung vornimmt. Dagegen ist der Inhalt lokaler Variablen unbestimmt und meist nicht null.Das Thema der globalen und lokalen Variablen spielt im Bereich der Funktionen eine besondere Rolle. Dort wird dieses Thema darum noch einmal aufgenommen.
Namensregeln und Syntaxgraph
In C++ unterliegen alle Namen, die vom Programmierer gewählt werden können, den gleichen Regeln. Diese Regeln gelten nicht nur für Variablen, sondern auch für Funktionen oder Klassen. In der englischen Literatur werden diese Namen als »identifier« bezeichnet. Das wird manchmal auch mit »Bezeichner« übersetzt. Ein Name muss mit einem Buchstaben oder einem Unterstrich beginnen und darf anschließend beliebig viele Buchstaben, Unterstriche und Ziffern enthalten. Das erste Zeichen darf keine Ziffer sein, damit der Compiler einen Namen leichter von einer Zahl unterscheiden kann. Die Buchstaben können klein oder groß sein. In C und C++ wird zwischen Klein- und Großschreibung unterschieden. Die Variable Anton ist eine andere Variable als die Variable ANTON oder anton. In der folgenden Abbildung wird die Regel zur Bildung eines Namens grafisch dargestellt.
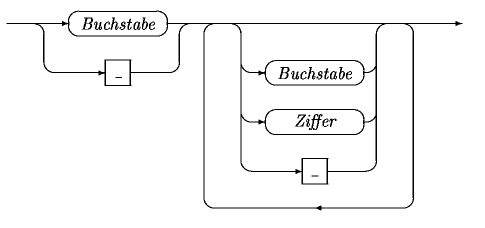
Zur Bildung eines Namens dürfen Sie dem Graph in Pfeilrichtung immer den Kurven nachfahren. Wenn Sie den Graph auf der rechten Seite verlassen haben, haben Sie einen zulässigen Namen gebildet. Sie werden feststellen, dass alle Namen mindestens ein Zeichen haben müssen, das entweder ein Buchstabe oder ein Unterstrich ist und dass dann beliebig viele Zeichen in beliebiger Reihenfolge verwendet werden dürfen. Dann dürfen zu den Buchstaben und dem Unterstrich auch Ziffern hinzukommen.
Syntaxgraph lesen
In rechteckigen Feldern finden Sie in Fettschrift so genannte Terminale. Das sind Zeichen oder Zeichenketten, die nicht weiter aufgelöst werden, sondern so, wie sie sind, eingesetzt werden. Im obigen Beispiel ist das der Unterstrich. In ovalen Feldern finden Sie in Kursivschrift Nonterminale, also Elemente, die einer näheren Beschreibung bedürfen. Diese folgt dann entweder im Text oder in weiteren Syntaxgraphen. Hier sind das die Buchstaben und Ziffern. (Der entsprechende Graph ist im Buch Einstieg in C++ nat³rlich abgebildet. Hier auf der Webseite bitte ich um Nachsicht, dass ich die Graphen der Einfachheit weglasse.)
Keine Sonderzeichen
Wie Sie sehen, gehen die Buchstaben von A bis Z und von a bis z. Grundsätzlich ist die Verwendung nationaler Sonderzeichen in Namen nicht erlaubt. Umlaute oder ein ß im Variablennamen führen also immer zu einer Fehlermeldung.Zu guter Letzt dürfen keine Befehle der Sprache C++ als Namen verwendet werden. Auch wenn Sie noch nicht alle Befehle von C++ kennen, können Sie diese leicht vermeiden, indem Sie Variablennamen wählen, die mindestens einen Großbuchstaben enthalten. Die Schlüsselwörter in C++ bestehen nur aus Kleinbuchstaben.
Schlüsselwörter
Die folgende Liste aus Stroustrup, Bjarne: Die C++ Programmiersprache. Addison-Wesley, München, 4. Aufl., 2000. S. 854 enthält die unter C++ verwendeten Schlüsselwörter. Sie dürfen nicht als Namen verwendet werden.[Schlüsselwörter von C++]
and and_eq asm auto bitand bitor bool break case catch char class compl const const_cast continue default delete do double dynamic_cast else enum explicit export extern false float for friend goto if inline int long mutable namespace new not not_eq operator or or_eq private protected public register reinterpret_cast return short signed sizeof static static_cast struct switch template this throw true try typedef typeid typename union unsigned using virtual void volatile wchar_t while xor xor_eq
Typen
Variablen haben immer einen Typ. Der Typ besagt, welche Informationen eine Variable aufnehmen kann. Der Typ bestimmt, wie viel Speicher für eine Variable benötigt wird. Ohne Typ können Sie keine Variable definieren. Der Compiler will zum Zeitpunkt der Übersetzung wissen, wie groß der erforderliche Speicher ist. Er überprüft auch, ob der Variablentyp im Kontext überhaupt passt. Diese Nörgeleien des Compilers sind nur zum Besten des Programmierers. Der Compiler erkennt so Flüchtigkeitsfehler, bevor sie Schaden anrichten können. In gewissen Grenzen ist C++ allerdings großzügig. Ähnliche Typen können direkt ineinander überführt werden, sofern kein Informationsverlust auftreten kann.
Informationsspeicherung
Bit
Die Informationen, die in Variablen abgelegt werden, werden im Hauptspeicher des Computers abgelegt. Wie funktioniert der Hauptspeicher eines Computers? Ein Computer arbeitet digital. Er verarbeitet also zwei Zustände: An und Aus. Der kleinste Speicher im Computer kann sich genau diese Information merken. Man kann »An« als 1 und »Aus« als 0 interpretieren. Die Informationseinheit, die eine Information 1 oder 0 unterscheiden kann, nennt man Bit.
Byte
Aus praktischen Gründen stellt man mehrere Bits zusammen. Dadurch ist es möglich, Zahlen darzustellen, die größer als 1 sind. Das Verfahren ist analog zu dem, das in unserem Zehnerzahlensystem angewandt wird, um Zahlen darzustellen, die größer als 9 sind: Man verwendet eine weitere Stelle und multipliziert die Stelle mit der Anzahl der Ziffern, die zur Verfügung stehen. Im Zehnersystem sind das zehn, im Binärsystem sind das zwei. Mit einem Bit lassen sich 0 und 1 darstellen. Mit zwei Bits gibt es die Kombinationen 00, 01, 10 und 11. Damit sind also mit zwei Bits die Zahlen 0, 1, 2 und 3 darstellbar. Ein weiteres Bit verdoppelt wiederum die Anzahl der Zustände. Die möglichen Kombinationen sind 000, 001, 010, 011, 100, 101, 110 und 111 und entsprechen den Zahlen von 0 bis 7. Aus technischen Gründen ist das Byte eine übliche Größe für die kleinste Zusammenfassung von Bits. Es besteht aus 8 Bits und kann damit 28 = 256 Zustände annehmen, also beispielsweise die Zahlen von 0 bis 255 oder von -128 bis 127.
Ganze Zahlen
int
Ein häufig benötigter Typ ist eine ganze Zahl, also eine ungebrochene Zahl ohne Nachkommastellen. Im Englischen und insbesondere im Computer-Umfeld spricht man von einem Integer. Der Typ einer Integer-Variable heißt int. Um eine Variable vom Typ int zu definieren, wird zuerst der Typ int genannt, dann folgt ein Leerraum und dann der Name der Variablen. Abgeschlossen wird die Definition durch ein Semikolon:
int Zaehler;
unsigned
Die Zahl, die die Variable Zaehler aufnimmt, kann positiv oder negativ sein. Sie können aber auch Variablen definieren, die nur positive Zahlen einschließlich der Null zulassen. Dazu stellen Sie das Schlüsselwort unsigned vor den Typ int:
unsigned int Zaehler;
Auf diese Weise wird nicht nur verhindert, dass die Variable Zaehler negativ wird. Der Zahlenbereich ins Positive wird verdoppelt.
short/long
Es gibt zwei besondere Fälle von ganzen Zahlen: short und long. Beide Attribute können dem Typ int vorangestellt werden. Die Namen der Attribute beziehen sich auf die Größe der maximal darstellbaren Zahl und damit auf den Speicher, der einer solchen Variablen zur Verfügung gestellt wird. Variablen vom Typ short oder long können vorzeichenlos definiert werden. Dann wird auch ihnen das Schlüsselwort unsigned vorangestellt:
unsigned short int Zaehler;
Wenn ein Attribut wie short oder unsigned verwendet wird, kann das Schlüsselwort int auch weggelassen werden. Damit sind auch folgende Definitionen zulässig und werden vom Compiler als attributierte Integer-Variablen verstanden:
[Integer-Variablen ohne int] unsigned short Zaehler; short Wenig; unsigned Positiv;
Eine Variable vom Typ short belegt immer mindestens zwei Bytes. Eine Variable vom Typ int ist mindestens so groß wie ein short. Eine Variable vom Typ long umfasst mindestens vier Bytes und ist mindestens so groß wie ein int. (vgl. Stroustrup, Bjarne: Die C++ Programmiersprache. Addison-Wesley, München, 4. Aufl. 2000. S.~81.) Wie viele Byte die verschiedenen Typen annehmen, ist nicht festgelegt, sondern liegt im Ermessen des Compiler-Herstellers.
Zahlenkodierung
Ganzzahlige Werte werden binär kodiert. Belegt eine Integer-Variable zwei Byte, so stehen 16 Bits zur Verfügung. %, die jeweils Null oder Eins sein können. %Die Zahl Null wird auf Bit-Ebene so darstellt, dass alle Bits Null sind. Zur Darstellung der Zahl Null werden alle Bits auf null gesetzt. Die Zahl Eins wird durch 15 Nullen und einer Eins kodiert. Die folgenden Zahlen zeigen die Binärkodierung.
| dual | dezimal |
|---|---|
| 0000000000000000 | 0 |
| 0000000000000001 | 1 |
| 0000000000000010 | 2 |
| 0000000000000011 | 3 |
| 0000000000000100 | 4 |
| 0000000000000101 | 5 |
| 0111111111111111 | 32.767 |
Nachdem die Kodierung der positiven Zahlen klar ist, stellt sich die Frage, wie negative Zahlen auf Bit-Ebene aussehen. Die Kodierung muss mit den üblichen Berechnungen möglichst kompatibel sein. Wenn Sie -1 und 1 addieren, soll möglichst 0 herauskommen. Dazu errechnen wir die -1, indem wir von 0 die Zahl 1 abziehen. Wenn wir mit der Stelle ganz rechts beginnen, ist 0-1=1. Dabei entsteht ein Übertrag, der auf die nächste Stelle umgelegt wird. Dadurch ensteht auch in der nächsten Stelle die Aufgabe 0-1, was wiederum 1 und einen Übertrag ergibt.
[Binäre Berechnung von 0 - 1]
0000
- 0001
Übertrag: 111
----
Ergebnis: 1111
Der Übertrag setzt sich also durch alle Stellen fort. Daraus ergibt sich, dass die Zahl -1 binär dargestellt wird, indem alle Bits auf Eins gesetzt werden. Sollte Ihnen das unlogisch erscheinen, überlegen Sie, welche Zahl null ergibt, wenn Sie eine Eins hinzuaddieren. Hier die Kontrollrechnung:
[Binäre Berechnung von -1 + 1]
1111
+ 0001
Übertrag: 111
----
Ergebnis: 0000
Die Zahlen -2, -3 und so weiter ergeben sich durch jeweiliges Dekrementieren, wie die folgende Tabelle zeigt.
| dual | dezimal |
|---|---|
| 0000000000000000 | 0 |
| 1111111111111111 | -1 |
| 1111111111111110 | -2 |
| 1111111111111101 | -3 |
| 1111111111111100 | -4 |
| 1111111111111011 | -5 |
| 1000000000000000 | -32.768 |
Dabei lässt sich leicht erkennen, dass das Vorzeichen der Zahl am ersten Bit abzulesen ist. Steht hier eine Eins, ist die Zahl negativ. Anhand der Kodierung lässt sich auch ermitteln, wie groß die größten und kleinsten Werte sind. Bei zwei Byte geht der Wert von -32.768 bis +32.767. Werden vier Byte eingesetzt, ergeben sich -2.147.483.648 bis +2.147.483.647.
| Ist das erste Bit einer binär kodierten Zahl 1, so ist die Zahl negativ. |
Zur Kontrolle berechnen wir noch einmal -3 + 5. Das Ergebnis sollte 2 sein.
[Binäre Berechnung von -3 + 5]
1101
+ 0101
Übertrag: 1 1
----
Ergebnis: 0010
unsigned
Werden die Variablen ohne Vorzeichen verwendet, so ist die Null die kleinste Zahl. Das erste Bit wird dann nicht zur Vorzeichenkodierung verwendet, sondern erhöht den maximalen Wert. So hat eine short-Variable dann einen Wertebereich von 0 bis 65.535. Wird die obere Grenze um eins erhöht, ergibt sich dann wieder die Null.
| dual | dezimal |
|---|---|
| 0000000000000000 | 0 |
| 0000000000000001 | 1 |
| 0000000000000010 | 2 |
| 0000000000000011 | 3 |
| 0000000000000100 | 4 |
| 0000000000000101 | 5 |
| 1111111111111110 | 65534 |
| 1111111111111111 | 65535 |
Überlauf
Etwas tückisch ist die Tatsache, dass Sie vor einem Überlauf der Grenzen von Integer-Werten nicht gewarnt werden. Erhöht sich der maximal darstellbare Wert einer Integer-Variablen um 1, so enthält sie anschließend den kleinstmöglichen Wert. Damit kann das Programm wunderbar weiterarbeiten. Es kann aber sein, dass Sie das nicht beabsichtigt haben. Es ist Ihre Aufgabe, dafür zu sorgen, dass ein solcher Überlauf nicht versehentlich auftritt.
Buchstaben
Ein wichtiger Datentyp ist der Buchstabe. Er macht es möglich, Texte zu verarbeiten. Das betrifft nicht nur die Textverarbeitungen, mit denen Sie Ihre Briefe schreiben. Es geht hier auch um das Erfassen, Sortieren und Ausgeben von tagtäglichen Daten wie Adressen oder Autokennzeichen.
char
Traditionell verwendet C++ den Datentyp char für Buchstaben. Dabei ist dieser Datentyp genau ein Byte groß. In einem Byte können Sie 256 Zustände speichern. Es gibt 26 Buchstaben, jeweils klein und groß, also werden mindestens 52 Zeichen benötigt. Dazu kommen die zehn Ziffern und einige Satzzeichen. Die ersten 128 Zeichen sind international genormt und bei allen ASCII-Zeichensätzen gleich. Die verbleibenden 128 Zustände werden für nationale Sonderzeichen wie die deutschen Umlaute oder die französischen Sonderzeichen verwendet.
wchar_t
Solange die nationalen Sonderzeichen nur diejenigen von Westeuropa umfassen, reicht ein Byte pro Buchstabe. Dieser Zeichensatz ist als ISO8859-1 genormt. Für russische oder türkische Zeichen gibt es wiederum einen anderen Zeichensatz. Aber mit welchem Recht kann man die arabischen, japanischen und hebräischen Zeichen ausschließen? Was passiert, wenn ein Programm russische, deutsche und hebräische Zeichen gleichzeitig benötigt? Für diese vielen Zeichen ist in einem einzelnen Byte kein Platz mehr. Mit zunehmender Internationalisierung muss damit gerechnet werden, dass ein neuer Code Verwendung findet, der mindestens zwei Bytes zur Darstellung eines Buchstabens verwendet. Einer der gebräuchlichsten Vertreter ist der UNICODE. Für solche Zeichensätze besitzt C++ einen speziellen Datentyp namens wchar_t. Wieviele Bytes er belegt, ist implementierungsabhängig.
Zahl oder Ziffer
Besonders verwirrend ist für den Anfänger oft die Unterscheidung zwischen Zahl und Ziffer. Eine Ziffer ist ein Zeichen (also quasi ein Buchstabe), das zur Darstellung von Zahlen (also Werten) dient. Im Zusammenhang mit der Programmierung ist eine Ziffer im Allgemeinen vom Typ char, also das Zeichen, das die Ziffer beispielsweise auf dem Bildschirm darstellt. Eine Zahl ist dagegen ein Wert, mit dem gerechnet werden kann.Um die Verwirrung komplett zu machen, sind Buchstaben intern eigentlich auch Zahlen. Jeder Buchstabe wird durch eine Zahl repräsentiert, die in ein Byte passt, also durch eine Zahl zwischen 0 und 255. Die Ziffern als Buchstaben sind ebenfalls intern als Zahl kodiert, aber nicht etwa gleich ihrem Zahlenwert. Sie finden im ASCII-Zeichensatz ihre Position ab der Nummer 48. Die Ziffer '0' wird also als 48 codiert, die Ziffer '1' als 49 und so fort. Dies muss besonders berücksichtigt werden, wenn Zahleneingaben von der Tastatur verarbeitet werden sollen. Wenn die einzelnen Ziffern als Buchstaben eingelesen werden, muss 48, also der Gegenwert der Ziffer '0' abgezogen werden, um ihren Zahlenwert zu erlangen. Übrigens ist ASCII nicht der einzige Zeichensatz. Beispielsweise ist auf den IBM-Großrechnern der Zeichensatz EBSDIC gebräuchlich. Das Beste ist, man trifft als Programmierer keine Annahmen darüber, wie die Ziffern kodiert sind.
Mit char rechnen
Besonders verwirrend scheint es, dass C++ durchaus erlaubt, mit Variablen vom Typ char+ zu rechnen. Tatsächlich stört es C+ auch nicht, wenn Sie einer Integer-Variablen einen Buchstaben zuweisen. Der Typ char besagt in erster Linie, dass ein Byte Speicher zur Verfügung steht. Der Inhalt kann sowohl als Zeichen als auch als kleine Zahl interpretiert werden.
unsigned char
Da eine Variable vom Typ char eigentlich nur eine kleinere int-Variable ist, gibt es auch ein Vorzeichen. Wie bei int ist auch die char-Variable zunächst vorzeichenbehaftet. Das hat Konsequenzen bei Umlauten. Wie oben erwähnt, liegen die nationalen Sonderzeichen in den hinteren 128 Positionen. Also steht bei einem nationalen Sonderzeichen das erste Bit auf 1. Das wird aber bei einer normalen char-Variablen als Zeichen für eine negative Zahl interpretiert. Um Missinterpretationen dieser Art zu vermeiden, sollten Sie eine char-Variable im Zweifelsfall mit dem Attribut unsigned versehen. Ansonsten kann es sein, dass ein 'ß' kleiner ist als ein 'a', da es durch das gesetzte erste Bit als negativ interpretiert wird. Eine Sortierung würde dann alle nationalen Sonderzeichen vor den eigentlichen Buchstaben erscheinen lassen. (Bei Verwendung von unsigned werden die nationalen Sonderzeichen hinter dem 'z' einsortiert, was auch etwas gewöhnungsbedürftig ist.)
Fließkommazahlen
In der realen Welt sind ganzzahlige Werte oft nicht ausreichend. Bei Gewichten, Geschwindigkeiten und anderen Werten aus der Physik ist immer mit Nachkommastellen zu rechnen. Dieser Tatsache kann sich auch eine Computersprache nicht entziehen. Eine solche Fließkommazahl besitzt zwei Komponenten. Die eine ist die Mantisse, und die andere ist der Exponent zur Basis 10. Der Exponent wird durch ein kleines oder großes E abgetrennt. Die Zahl 1.5E2 hat den Gegenwert von 150. Dabei ist 1.5 die Mantisse, 2 ist der Exponent.
float
Der einfachste Typ mit Nachkommastellen heißt float. Die Zahlen dieses Typs sind binär kodiert, damit sie effizient im Computer verarbeitet werden können. Die Zahl lässt ganzzahlige, aber auch negative Exponenten zu. Dadurch sind nicht nur extrem große Zahlen darstellbar, sondern auch sehr kleine Brüche. Die Speicheranforderung einer float-Variablen ist nicht sehr hoch, typischerweise liegt sie bei vier Bytes. Dennoch können Zahlen in der Größenordnung von etwa 1038 dargestellt werden. Dafür geht eine solche Variable Kompromisse in der Genauigkeit der Mantisse ein.
double
Reicht die Genauigkeit nicht aus oder werden Größenordnungen benötigt, die über die Kapazität einer float-Variablen hinausgehen, steht der Typ double zur Verfügung. Der Name bedeutet »doppelt« und bezieht sich auf die Genauigkeit. Die Genauigkeit geht zu Lasten des Speichers. Auf vielen Compilern belegt eine double-Variable auch doppelt so viel Speicher wie eine float-Variable. Und natürlich erhöht die Berechnung doppelt genauer Werte auch die Laufzeit eines Programms.
long double
Werden besonders genaue Werte benötigt, verfügt ein ANSI-C++-Compiler über einen Datentyp, der noch genauer ist als der Typ double. Das ist der Typ long double. Dieser belegt je nach Compiler 10 bis 16 Bytes.
Ungenauigkeit
Beim Umgang mit Fließkommazahlen ergeben sich leicht Genauigkeitsprobleme. Das beruht zum einen auf der begrenzten Zahl von Stellen der Mantisse. Bei dezimalen Nachkommastellen kann aber auch die interne binäre Kodierung eine Ursache sein. Sie können dies feststellen, wenn Sie eine Variable auf -1,0 setzen und schrittweise um 0,1 erhöhen. Sie werden auf diese Weise auf den meisten Sysemen den Wert 0,0 nicht exakt treffen. Der Grund ist, dass 0,1 in binärer Darstellung ebenso eine Periode darstellt, wie ein Drittel in Dezimaldarstellung.
Das 0,1-Problem
Um 0,1 dezimal im binären Zahlensystem darzustellen, müssen binäre Nachkommastellen verwendet werden. Binäre Nachkommastellen müssen Sie sich so vorstellen, dass 0,1 ein Halb, 0,01 ein Viertel und 0,001 ein Achtel ist. Zur Darstellung eines Zehntels ist ein Achtel zu viel. Ein Sechszehntel ist 0,0625. Es verbleiben 0,0375 zu einem Zehntel. Ein Zweiunddreißigstel sind 0,03125. Es bleiben 0,00625. Ein 256stel sind 0,00390625. Durch Weiterberechnen kommen Sie auf eine binäre Darstellung von 0,000110011001111 und haben immer noch etwas Rest. Wenn Sie das Ganze zu Ende rechnen, werden Sie feststellen müssen, dass es niemals aufgeht. Und so wie einige Taschenrechner ein Problem damit haben, bei drei Dritteln auf ein Ganzes zu kommen, haben Computer mit ihren binär kodierten Fließkommazahlen ein Problem bei der Berechnung von zehn Zehnteln.
Festkommazahlen
In einigen Programmiersprachen und auch in Datenbanken gibt es explizite Typen mit einer dezimalen Anzahl von Nachkommastellen. Solche Werte sind vor allem bei Währungen sehr exakt. Allerdings hat die Genauigkeit bereits an der nächsten Tankstelle ihr Ende, wo der Literpreis auch 0,9 Cent enthält. C++ kennt keine Nachkomma-Variablen, sondern nur Fließkomma-Typen. Das heißt, dass so viele Nachkommastellen gebildet werden, wie benötigt werden und darstellbar sind.
Größen und Limits
Die Sprache C++ legt die Speicheranforderung der meisten Typen nicht fest. Solche Implementierungsdetails werden den Compilern überlassen. Lediglich die Qualitätsunterschiede zwischen den Typen werden gesichert. Sie können sich also darauf verlassen, dass ein short nicht größer ist als ein long. Die folgende Tabelle gibt eine Übersicht, welche Größenordnungen in der Praxis derzeit üblich sind.
| Typ | Typische Größe |
|---|---|
| char | 1 Byte |
| short int | 2 Bytes |
| int | 2 oder 4 Bytes |
| long int | 4 Bytes |
| float | 4 Bytes |
| double | 8 Bytes |
| long double | 12 Bytes |
Welche Größe welcher Typ letztlich wirklich hat, hängt nicht von der Laune eines Compiler-Herstellers ab, sondern beispielsweise auch von der Hardware- oder Betriebssystem-Architektur. Die gängigen Maschinen haben derzeit meist eine Wortbreite von 32 Bit, also 4 Bytes. Entsprechend können vier Bytes sehr effizient verarbeitet werden. Die nächste Generation der 64-Bit-Systeme steht aber bereits vor der Tür. Auf solchen Systemen wird man vermutlich den Typ long mit 8 Bytes implementieren, da ein kürzerer Typ ineffizient wäre. Zu den Zeiten, als C++ entstand, waren 16-Bit-Maschinen die Regel. Hätte man damals den Typ int auf zwei Bytes festgelegt, würden die zukünftigen Compiler Aufwand betreiben müssen, nur um einen 64-Bit-Speicherplatz auf 16 Bit zu begrenzen.
sizeof
Wenn Sie konkret die Größe eines Typs wissen müssen, können Sie die Pseudofunktion sizeof() verwenden. Diese liefert die Größe eines Typs oder einer Variablen. Die folgende Beispielzeile gibt aus, wie viele Bytes der Typ double auf Ihrem System beansprucht.
cout << sizeof(double) << endl;
Genauso kann zwischen die Klammern von sizeof eine Variable oder ein selbstdefinierter Typ gestellt werden. Das Ergebnis ist immer der Speicherbedarf in Bytes. In dieser Flexibilität hat sizeof() eine Sonderstellung. Ansonsten können Funktionen nur Werte oder Variablen übergeben werden. Deren Typ wird zudem vom Compiler geprüft.
limits.h
In der Datei limits.h werden die Größen der Grundtypen festgelegt. So findet sich hier die Definition von INT_MAX. Dies ist der höchste Wert, den eine Integer-Variable annehmen kann. Mit CHAR_MAX erfahren Sie die gleiche Information zum Typ char. Es wird Sie nicht verwundern, dass der Wert LONG_MAX den maximalen Wert liefert, den eine Variable vom Typ long annehmen kann. Dafür könnte ich Sie wahrscheinlich mit SHRT_MAX als dem größten Wert für eine short-Variable überraschen. Denn Sie würden nach den Vorgaben vermuten, dass noch ein O darin vorkommt. (Es geht das Gerücht um, dass die Geheimdienste zur Zeit des kalten Krieges solche Wunderlichkeiten erzwungen hätten, damit der Feind nach einer Besetzung Schwierigkeiten haben würde, mit den Computern umzugehen.)
| Konstante | Bedeutung |
|---|---|
| INT_MAX | Höchster Wert einer int-Variablen |
| INT_MIN | Niedrigster Wert einer int-Variablen |
| UINT_MAX | Höchster Wert einer unsigned int-Variablen |
| CHAR_MAX | Höchster Wert einer char-Variablen |
| CHAR_MIN | Niedrigster Wert einer char-Variablen |
| UCHAR_MAX | Höchster Wert einer unsigned char-Variablen |
| SHRT_MAX | Höchster Wert einer short-Variablen |
| SHRT_MIN | Niedrigster Wert einer short-Variablen |
| USHRT_MAX | Höchster Wert einer unsigned short-Variablen |
| LONG_MAX | Höchster Wert einer long-Variablen |
| LONG_MIN | Niedrigster Wert einer long-Variablen |
| ULONG_MAX | Höchster Wert einer unsigned long-Variablen |
Zu all diesen Definitionen gibt es auch eine passende Variation mit der Vorsilbe MIN, mit der Sie erfahren, welches der kleinstmögliche Wert des entsprechenden Typs ist. Schließlich können Sie den jeweiligen Definitionen ein großes U voranstellen, um zu erfahren, welches der größte Wert ist, wenn der Typ das Attribut unsigned trägt. Wenn Sie Ihre Kollegen einem kurzen Intelligenztest unterziehen wollen, fragen Sie doch mal, warum ULONG_MIN nicht definiert wurde.
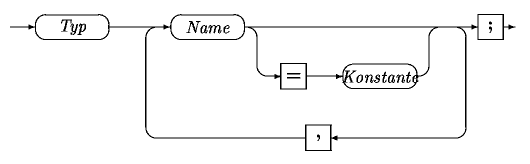
Syntax der Variablendefinition
Variablendefinition
Im Syntaxgraph der Variablendefinition wird dargestellt, wie eine Variablendefinition mit den grundlegenden Typen syntaktisch korrekt ist. Zuerst wird der Typ der Variablen genannt. Es folgt der Name der Variablen, der bereits als Syntaxgraph dargestellt wurde. Durch Anhängen eines Gleichheitszeichens und einer Konstante kann eine Initialisierung erfolgen. Die Variablendefinition wird durch ein Semikolon abgeschlossen. Es können mehrere Variablen in einer Anweisung definiert werden, indem man sie durch ein Komma voneinander trennt.
[Syntaxgraph einer Variablendefinition]
Die bisher vorgestellten Typen werden in dem folgenden Syntaxgraph dargestellt.
[Syntaxgraph einer Typbeschreibung]
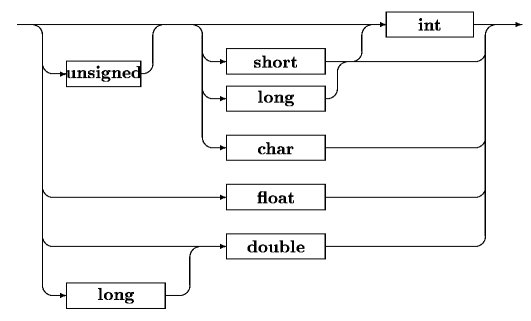
Es ist zu erkennen, dass der Typ char, int, float oder double sein kann. Vor char und den Integertypen darf unsigned gestellt werden. Vor int können die Attribute long und short verwendet werden. Wird eines dieser beiden Attribute verwendet, muss int nicht mehr explizit genannt werden.
Konstanten
Eine Konstante ist ein unveränderlicher Wert. Alle Zahlen in einem Programm sind Konstanten, da ihr Wert, im Gegensatz zu Variablen, nicht geändert werden kann. In C++ haben auch Konstanten einen Typ.
Ganze Zahlen
Am einfachsten sind ganzzahlige Konstanten zu verstehen. Es sind Zahlen wie 5, -3, 17 oder 5498. Dabei ist nur darauf zu achten, dass eine Zahlenkonstante nur aus Ziffern besteht und keine Leerzeichen oder andere Sonderzeichen darin enthalten sind. Einer negativen Zahl wird das Minuszeichen vorangestellt. Bei positiven Zahlen ist das Pluszeichen erlaubt, aber nicht erforderlich.
| Eine dezimale, ganzzahlige Konstante ist 0 oder beginnt mit einer Ziffer ungleich null. Ihr folgen beliebig viele weitere Ziffern einschließlich der Null. |
[Syntaxgraph einer dezimalen Zahlenkonstante]
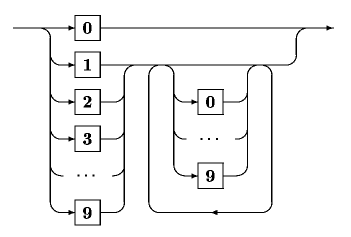
Die folgende Tabelle zeigt einige Beispiele unzulässiger Zahlenkonstanten.
| Konstante | Grund |
|---|---|
| 1 234 | Es ist ein Leerzeichen zwischen 1 und 2. |
| 1.234 | Es ist ein Tausenderpunkt zwischen 1 und 2. |
| 1- | Das Vorzeichen muss vor der Zahl stehen. |
| 12DM | Einheiten sind nicht erlaubt. |
Führende Null
Neben den Dezimalzahlen gibt es in C++ auch die Möglichkeit, das oktale und das hexadezimale Zahlensystem zur Darstellung von Konstanten zu verwenden. Diese Möglichkeit ist in erster Linie für Programmierer interessant, die auf Controller-Ebene programmieren. Folgende Regel ist wichtig:
| Jede ganzzahlige Konstante, die mit einer Null beginnt, wird als nicht dezimale Konstante interpretiert. Vermeiden Sie also, einer Konstanten eine überflüssige Null voranzustellen, sofern Sie nicht genau wissen, was Sie tun. |
Andere Zahlensysteme
Beginnt eine Zahlenkonstante mit Null und folgt der Null ein x, ist es eine hexadezimale Konstante. Das ist eine Zahl zur Basis 16, die die Ziffern 0 bis 9 und die Buchstaben A bis F für die Ziffern 10 bis 15 verwendet. In diesem Fall dürfen auch die Kleinbuchstaben a bis f verwendet werden. Folgt der Null eine Ziffer, ist es eine Oktalzahl, also eine Zahl zur Basis 8. Erlaubte Ziffern sind die Ziffern von 0 bis 7.Die folgende Tabelle zeigt den unterschiedlichen Wert der Ziffernfolge 11. %in den verschiedenen Zahlensystemen.
| Konstante | Zahlensystem | Dezimaler Wert |
|---|---|---|
| 11 | dezimal (Basis 10) | 1*10 + 1*1 = 11 |
| 011 | oktal (Basis 8) | 1*8 + 1*1 = 9 |
| 0x11 | hexadezimal (Basis 16) | 1*16 + 1*1 = 17 |
Zehnersystem
Die Berechnung der Werte anderer Zahlensysteme erfolgt genauso, wie Sie es intuitiv mit dem normalen, dezimalen Zahlensystem auch tun. Im Dezimalsystem multiplizieren Sie jede Stelle mit der zugehörigen Zehnerpotenz. Der Exponent beginnt rechts mit der Null. Damit ist der Faktor, mit der die äußerste rechte Ziffer multipliziert wird, 100 oder 1. Die zweite Stelle von rechts wird mit 101, also 10, multipliziert. Es geht weiter mit 102 gleich 100, 103 gleich 1000 und so weiter.
Hexadezimale Zahlen
Die hexadezimalen (Es gibt einige Programmierer mit humanistischer Bildung, die darauf bestehen, dass es eigentlich sedezimal heißen müsste, weil hexa aus dem Griechischen und decem aus dem Lateinischen stamme. Sie werden sich nicht viele Freunde machen, wenn Sie diese Erkenntnis verbreiten und Ihre Kollegen damit auf ihre Bildungslücken in Latein und Griechisch stoßen. Also sollten Sie diese Anmerkung schnell wieder vergessen.) Zahlen haben die Basis 16. Damit reichen die dezimalen Ziffern 0 bis 9 nicht für eine hexadezimale Ziffer aus. Darum werden die Buchstaben A bis F zu Hilfe genommen. A hat den Wert 10, B ist 11 und so weiter. Schließlich hat F als höchste Ziffer den Wert 15. Das Vorgehen zur Ermittlung des Wertes einer hexadezimalen Konstante entspricht dem im dezimalen System. Die äußerste rechte Stelle bleibt, weil auch 160=1 ist. Die nächste Stelle wird mit 16 multipliziert, die darauf folgende Stelle mit 162=256 und so fort. Damit wäre 0x168 gleich 1*256 + 6*16 + 8, also dezimal 360.
| Eine hexadezimale, ganzzahlige Konstante beginnt immer mit der Zeichenfolge 0x. Ihr folgen beliebig viele weitere Ziffern zwischen 0 und 9 bzw. A bis F. Die Ziffern A bis F dürfen auch als Kleinbuchstaben dargestellt werden. |
Der Syntaxgraph einer hexadezimalen Zahlenkonstante ist im Buch Einstieg in C++ nat³rlich abgebildet. Hier auf der Webseite bitte ich um Nachsicht, dass ich diesen Graph der Einfachheit weglasse.)
Oktale Zahlen
Oktale (Der Begriff »oktal« leitet sich von Oktopus (Krake) her. Da Kraken nur acht Arme haben, können sie nicht bis zehn zählen und haben darum dieses Zahlensystem erfunden, damit es die Krakenkinder leichter in der Schule haben.) Zahlen bestehen aus den Ziffern 0 bis 7. Hier werden die Stellen mit Achterpotenzen berechnet. Sie haben von rechts nach links also die Faktoren 1, 8, 64 und so fort. Die Konstante 0167 wäre umgerechnet also 1*64 + 6*8 + 7. Damit entspricht die Konstante 0167 dem dezimalen Wert 119.
| Eine oktale, ganzzahlige Konstante beginnt immer mit der Null. Ihr folgen beliebig viele weitere Ziffern zwischen 0 und 7. |
Der Syntaxgraph einer oktalen Zahlenkonstante ist im Buch Einstieg in C++ nat³rlich abgebildet. Hier auf der Webseite bitte ich um Nachsicht, dass ich diesen Graph der Einfachheit weglasse.)
Fließkommakonstanten
Fließkommazahlen sind Zahlen mit Nachkommastellen. Leider ist das Komma als Dezimaltrennzeichen international nicht üblich. Vor allem im englischsprachigen Raum wird stattdessen der Punkt verwendet. Dementsprechend versteht C++ die Schreibweise 1,2 nicht, sondern bevorzugt 1.2.
Mantisse
Um eine Fließkommakonstante anzugeben, wird zunächst die Mantisse beschrieben. Die Mantisse ist der Anteil einer Fließkommakonstante ohne Exponenten. Sie beginnt mit einem optionalen Vorzeichen, auf das eine dezimale Ganzzahl folgt. Dann können der Dezimalpunkt und die Nachkommastellen als dezimale Ganzzahl erscheinen. Steht vor dem Dezimalpunkt nur eine Null, kann sie weggelassen werden.
Exponent
Wie bei einem Taschenrechner lassen sich auch Exponenten verwenden. Dabei wird als Basis stillschweigend 10 vereinbart. Um den Exponenten von der Mantisse zu trennen, wird ein großes oder kleines E verwendet. Der Exponent selbst ist eine ganzzahlige Dezimalkonstante, kann also auch negativ sein. Beispiel:
| Exponentialdarstellung | Wert | Darstellung ohne Exponent |
|---|---|---|
| 1E3 | 103 | 1000.0 |
| 1E0 | 100 | 1.0 |
| 1E-1 | 10-1 | 0.1 |
| 1E-3 | 10-3 | 0.001 |
[Syntaxgraph einer Fließkommakonstante]
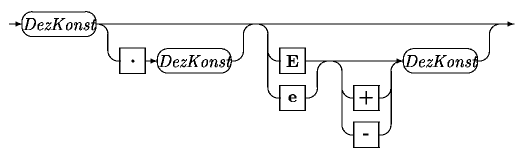
Im Syntaxgraph wird dreimal auf DezKonst verwiesen. Dabei handelt es sich um eine dezimale Konstante, so wie sie bereits im Syntaxgraph beschrieben wurde.
Optional kann einer Fließkommakonstante ein f zur Kennzeichnung angehängt werden. Es ist allerdings eher üblich, eine Fließkommakonstante durch das Anhängen von .0 gegen eine ganzzahlige Konstante abzugrenzen.
Buchstabenkonstanten
Einzelne Buchstaben, also Konstanten für den Typ char werden in Hochkommata gesetzt. Diese Form der Darstellung verbessert die Lesbarkeit für den Menschen. Intern verwendet der Computer für Buchstaben Zahlen.
Der Syntaxgraph einer Zeichenkonstante ist im Buch Einstieg in C++ nat³rlich abgebildet. Hier auf der Webseite bitte ich um Nachsicht, dass ich diesen Graph der Einfachheit weglasse.)
ASCII
Welche Zeichen auf welche Zahlen abgebildet werden, hängt vom Zeichensatz ab. Auf den meisten Systemen wird heute ASCII (American Standard Code for Information Interchange) verwendet. Im ASCII-Zeichensatz werden die ersten Positionen für Kontrollzeichen verwendet. Darin befindet sich beispielsweise das Zeilenendezeichen mit der Nummer 10 oder das Piepzeichen mit der Nummer 7. Es folgen die Sonder- und Satzzeichen.
Ziffern
Ab der Nummer 48 beginnen im ASCII-Zeichensatz die Ziffern. Die '0' ist als 48 kodiert, die '1' als 49. So geht es fort bis zur '9' als 57. Als Programmierer sollten Sie sehr genau zwischen einer '0' und einer 0 unterscheiden. Wenn der Anwender Zahlen eintippt, so sind diese eine Folge von Buchstaben. Um aus diesen Buchstaben Zahlen zu berechnen, müssen Sie den Wert der Ziffer '0' abziehen. Aus der '3' wird eine 3, indem Sie den Wert '0' subtrahieren. Sie finden dazu ein Programmbeispiel.
Buchstaben
Die Buchstaben beginnen mit dem Großbuchstaben 'A' ab 65. Danach folgen die Kleinbuchstaben mit 'a' ab Nummer 97. Die Buchstaben sind durchgehend aufsteigend sortiert von A bis Z. Internationale Sonderzeichen wie die deutschen Umlaute befinden sich jenseits der 128. Wo sich beispielsweise das 'ö' befindet und ob es überhaupt vorhanden ist, hängt vom Zeichensatz ab. In der westlichen Welt finden Sie unter UNIX, Linux und MS-Windows meist den Zeichensatz ISO-8859-1 (Latin-1). Osteuropäische Sprachen verwenden Latin-2, und ISO 8859-9 beispielsweise ist ein türkisch angepasster Latin-1-Zeichensatz. Um möglichst alle Sprachen mit dem gleichen Zeichensatz verarbeiten zu können, wurde UNICODE eingeführt. Dazu reicht allerdings ein Byte nicht mehr aus, sondern es werden pro Zeichen zwei Byte verwendet.
ASCII oder EBSDIC
Verlassen Sie sich nicht blind auf die Position der einzelnen Zeichen im Zeichensatz. Zwar ist der ASCII-Zeichensatz auf allen PCs und allen gängigen UNIX-Maschinen zu Hause, aber beispielsweise IBM-Großrechner arbeiten üblicherweise mit dem EBSDIC-Zeichensatz, der völlig anders aufgebaut ist. Sie können sich bestenfalls darauf verlassen, dass Buchstaben und Ziffern in sich aufsteigend sortiert sind und dass die Ziffern lückenlos aufeinander folgen.
Kontrollzeichen
Um vom Zeichensatz der Maschine unabhängig zu sein, definiert C++ einige wichtige Sonderzeichen durch Voranstellen eines Backslashs (\). Der Backslash ähnelt dem Schrägstrich (/), den man auf einer deutschen Tastatur über der 7 findet, steht aber in der umgekehrten Richtung. Auf deutschen Tastaturen erzeugt man ihn durch die Kombination der Tasten AltGr und ß. Zum Backslash gehört immer mindestens ein Zeichen, das die Bedeutung der Sequenz kodiert. Die nachfolgende Tabelle zeigt die wichtigsten Sonderzeichen.
| Sequenz | Bedeutung |
|---|---|
| \n | Neue Zeile |
| \t | Tabulatorzeichen |
| \b | Backspace, also Zeichen rückwärts |
| \f | Seitenvorschub |
| \0 | Echte 0, also nicht die Ziffer '0' |
| \\ | Ausgabe eines Backslashs |
| \" | Ausgabe eines Anführungszeichens |
| \' | Ausgabe eines Hochkommas |
| \0nnn | Oktalzahl nnn bestimmt das Zeichen |
| \0xnn | Hexadezimalzahl nn bestimmt das Zeichen |
Zeichenketten
Zeichenketten bestehen aus mehreren, aneinander gehängten Buchstaben. Alles was zur Zeichenkettenkonstante gehören soll, wird in Anführungszeichen eingeschlossen. In einer Zeichenkette können alle Zeichen verwendet werden, die auch in einer Buchstabenkonstante verwendet werden, also auch die Kontrollzeichen. Beispielsweise würde die folgende Zeichenkette zwei Zeilen darstellen:
"Dies ist eine Zeichenkette\n aus zwei Zeilen"
Der Syntaxgraph einer Zeichenkettenkonstante ist im Buch Einstieg in C++ nat³rlich abgebildet. Hier auf der Webseite bitte ich um Nachsicht, dass ich diesen Graph der Einfachheit weglasse.)
Da Zeichenketten zusammengesetzte Elemente sind, können sie nicht so einfach behandelt werden wie Zahlen oder einzelne Buchstaben. Zu Anfang werden sie darum nur als Konstanten für die Ausgabe der Programme verwendet. Wie man Variablen für Zeichenketten definiert und wie man sie zuweist und verarbeitet, wird an anderer Stelle beschrieben, wenn es um zusammengesetzte Typen geht.
Symbolische Konstanten
Zahlenkonstanten, die ohne weiteren Kontext im Programm stehen, haben keinen Dokumentationswert und führen zu Verwechslungen. Verwenden Sie an einer Stelle im Programm eine 8, so wird sich sofort jeder Leser fragen, was diese 8 eigentlich bedeuten soll. Nehmen wir an, es handele sich um die Regelarbeitszeit pro Tag, so würde es die Lesbarkeit des Programms wesentlich verbessern, wenn Sie statt der 8 das Wort »RegelArbeitsZeit« verwenden. Damit wird sofort deutlich, was die Zahl zu bedeuten hat.Um das Wort mit der Zahl zu verbinden, deklarieren Sie eine Konstante. Eine Konstante entspricht in C++ einer unveränderbaren Variablen. Sie hat einen Typ und einen Namen wie eine Variable, kann aber nicht geändert werden. Da die Konstante nicht änderbar ist, muss sie bei ihrer Deklaration initialisiert werden. Eine Konstantendeklaration sieht also aus wie eine Variablendefinition mit Initialisierung, der man das Schlüsselwort const vorangestellt hat.
[Deklaration einer Konstanten] const int RegelArbeitsZeit = 8;
Kein Speicher
Konstanten benötigen im Gegensatz zu Variablen keinen Speicher, da sie nur einen Namen für einen konstanten Wert einführen, der nach der Kompilierung restlos verschwindet.
Änderungsfreudig
Es gibt zwei wichtige Gründe dafür, Konstanten zu deklarieren. Erstens führt die Verwendung von Konstanten zu einer besseren Lesbarkeit des Programms. Zweitens ist bei Änderung des Wertes einer Konstante nur eine Stelle im Programm zu korrigieren. Würde im obigen Beispiel die Regelarbeitszeit eines Tages nicht mehr acht, sondern sieben Stunden betragen, müssten Sie das Programm nur an einer Stelle zu ändern. Hätten Sie aber im Programm überall die Zahl stehen, müssten Sie nach jedem Vorkommen der 8 suchen. Dabei müssten Sie zusätzlich aufpassen, ob diese 8 auch wirklich die Regelarbeitszeit und nicht vielleicht die maximale Größe einer Arbeiterkolonne oder der Mindesttariflohn der Reinigungskräfte ist. Es gibt eine Faustregel, die besagt, dass alle Zahlen außer 0 und 1 mit Namen deklariert werden sollten. Der Aufwand, die Konstanten zunächst zu deklarieren, steht in keinem Verhältnis zu dem Nutzen in Bezug auf Flexibilität und Lesbarkeit.
Alte Form
Diese Form der Deklaration von Konstanten gibt es in C erst seit Einführung des ANSI-Standards. Vorher wurden Konstanten über den Präprozessor des Compilers gesetzt. Der Präprozessor kann mit dem Befehl #define eine textuelle Ersetzung herbeiführen. So würde folgender Befehl die Regelarbeitszeit von oben definieren.[Deklaration einer Konstanten]
#define RegelArbeitsZeit 8
Das führt dazu, dass der Präprozessor im Quelltext, kurz bevor der Compiler ihn übersetzt, überall eine 8 einsetzt, wo der Programmierer das Wort »RegelArbeitsZeit« geschrieben hat. Auf den ersten Blick ist der Effekt derselbe. In zwei wichtigen Aspekten unterscheiden sich die Mechanismen: Erstens legt die C++-Schreibweise auch den Typ der Konstanten fest, und zweitens können die C++-Konstanten auch mit Werten initialisiert werden, die vorher im Programm errechnet wurden.